Typically, the use of large language models (LLMs) in the enterprise falls into two broad categories. The first one is where the LLM automates a language-related task such as writing a blog post, drafting an email, or improving the grammar or tone of an email you have already drafted. Most of the time these sorts of tasks do not involve confidential company information.
The second category involves processing internal company information, such as a collection of documents (PDFs, spreadsheets, presentations, etc.) that need to be analyzed, summarized, queried, or otherwise used in a language-driven task. Such tasks include asking detailed questions about the implications of a clause in a contract, for example, or creating a visualization of sales projections for an upcoming project launch.
There are two reasons why using a publicly available LLM such as ChatGPT might not be appropriate for processing internal documents. Confidentiality is the first and obvious one. But the second reason, also important, is that the training data of a public LLM did not include your internal company information. Hence that LLM is unlikely to give useful answers when asked about that information.
Enter retrieval-augmented generation, or RAG. RAG is a technique used to augment an LLM with external data, such as your company documents, that provide the model with the knowledge and context it needs to produce accurate and useful output for your specific use case. RAG is a pragmatic and effective approach to using LLMs in the enterprise.
In this article, I’ll briefly explain how RAG works, list some examples of how RAG is being used, and provide a code example for setting up a simple RAG framework.
How retrieval-augmented generation works
As the name suggests, RAG consists of two parts—one retrieval, the other generation. But that doesn’t clarify much. It’s more useful to think of RAG as a four-step process. The first step is done once, and the other three steps are done as many times as needed.
The four steps of retrieval-augmented generation:
- Ingestion of the internal documents into a vector database. This step may require a lot of data cleaning, formatting, and chunking, but this is a one-time, up-front cost. (For a quick primer on vector databases see this article.)
- A query in natural language, i.e., the question a human wants to ask the LLM.
- Augmentation of the query with data retrieved using similarity search of the vector database. This step is where context from the document store is added to the query before the query is submitted to the LLM. The prompt instructs the LLM to respond in the context of the additional content. The RAG framework does this work behind the scenes by means of a component called a retriever, which executes the search and appends the relevant context.
- Generation of the response to the augmented query by the LLM.
By focusing the LLM on the document corpus, RAG helps to ensure that the model produces relevant and accurate answers. At the same time, RAG helps to prevent arbitrary or nonsensical answers, which are commonly referred to in the literature as “hallucinations.”
From the user perspective, retrieval-augmented generation will seem no different than asking a question to any LLM with a chat interface—except that the system will know much more about the content in question and will give better answers.
The RAG process from the point of view of the user:
- A human asks a question of the LLM.
- The RAG system looks up the document store (vector database) and extracts content that may be relevant.
- The RAG system passes the user’s question, plus the additional content retrieved from the document store, to the LLM.
- Now the LLM “knows” to provide an answer that makes sense in the context of the content retrieved from the document store (vector database).
- The RAG system returns the response from the LLM. The RAG system can also provide links to the documents used to answer the query.
Use cases for retrieval-augmented generation
The use cases for RAG are varied and growing rapidly. These are just a few examples of how and where RAG is being used.
Search engines
Search engines have implemented RAG to provide more accurate and up-to-date featured snippets in their search results. Any application of LLMs that must keep up with constantly updated information is a good candidate for RAG.
Question-answering systems
RAG has been used to improve the quality of responses in question-answering systems. The retrieval-based model finds relevant passages or documents containing the answer (using similarity search), then generates a concise and relevant response based on that information.
E-commerce
RAG can be used to enhance the user experience in e-commerce by providing more relevant and personalized product recommendations. By retrieving and incorporating information about user preferences and product details, RAG can generate more accurate and helpful recommendations for customers.
Healthcare
RAG has great potential in the healthcare industry, where access to accurate and timely information is crucial. By retrieving and incorporating relevant medical knowledge from external sources, RAG can assist in providing more accurate and context-aware responses in healthcare applications. Such applications augment the information accessible by a human clinician, who ultimately makes the call and not the model.
Legal
RAG can be applied powerfully in legal scenarios, such as M&A, where complex legal documents provide context for queries, allowing rapid navigation through a maze of regulatory issues.
Introducing tokens and embeddings
Before we dive into our code example, we need to take a closer look at the document ingestion process. To be able to ingest docs into a vector database for use in RAG, we need to pre-process them as follows:
- Extract the text.
- Tokenize the text.
- Create vectors from the tokens.
- Save the vectors in a database.
What does this mean?
A document may be PDF or HTML or some other format, and we don’t care about the markup or the format. All we want is the content—the raw text.
After extracting the text, we need to divide it into chunks, called tokens, then map these tokens to high-dimensional vectors of floating point numbers, typically 768 or 1024 in size or even larger. These vectors are called embeddings, ostensibly because we are embedding a numerical representation of a chunk of text into a vector space.
There are many ways to convert text into vector embeddings. Usually this is done using a tool called an embedding model, which can be an LLM or a standalone encoder model. In our RAG example below, we’ll use OpenAI’s embedding model.
A note about LangChain
LangChain is a framework for Python and TypeScript/JavaScript that makes it easier to build applications that are powered by language models. Essentially, LangChain allows you to chain together agents or tasks to interact with models, connect with data sources (including vector data stores), and work with your data and model responses.
LangChain is very useful for jumping into LLM exploration, but it is changing rapidly. As a result, it takes some effort to keep all the libraries in sync, especially if your application has a lot of moving parts with different Python libraries in different stages of evolution. A newer framework, LlamaIndex, also has emerged. LlamaIndex was designed specifically for LLM data applications, so has more of an enterprise bent.
Both LangChain and LlamaIndex have extensive libraries for ingesting, parsing, and extracting data from a vast array of data sources, from text, PDFs, and email to messaging systems and databases. Using these libraries takes the pain out of parsing each different data type and extracting the content from the formatting. That itself is worth the price of entry.
A simple RAG example
We will build a simple “Hello World” RAG application using Python, LangChain, and an OpenAI chat model. Combining the linguistic power of an LLM with the domain knowledge of a single document, our little app will allow us to ask the model questions in English, and it will answer our questions by referring to content in our document.
For our document, we’ll use the text of President Biden’s February 7, 2023, State of the Union Address. If you want to try this at home, you can download a text document of the speech at the link below.
A production-grade version of this app would allow private collections of documents (Word docs, PDFs, etc.) to be queried with English questions. Here we are building a simple system that does not have privacy, as it sends the document to a public model. Please don’t run this app using private documents.
We will use the hosted embedding and language models from OpenAI, and the open-source FAISS (Facebook AI Similarity Search) library as our vector store, to demonstrate a RAG application end to end with the least possible effort. In a subsequent article we will build a second simple example using a fully local LLM with no data sent outside the app. Using a local model involves more work and more moving parts, so it is not the ideal first example.
To build our simple RAG system we need the following components:
- A document corpus. Here we will use just one document.
- A loader for the document. This code extracts text from the document and pre-processes (tokenizes) it for generating an embedding.
- An embedding model. This model takes the pre-processed document and creates embeddings that represent the document chunks.
- A vector data store with an index for similarity searching.
- An LLM optimized for question answering and instruction.
- A chat template for interacting with the LLM.
The preparatory steps:
pip install -U langchain pip install -U langchain_community pip install -U langchain_openai
The source code for our RAG system:
# We start by fetching a document that loads the text of President Biden’s 2023 State of the Union Address
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./stateOfTheUnion2023.txt')
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai.embeddings import OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] =<you will need to get an API ket from OpenAI>
# We load the document using LangChain’s handy extractors, formatters, loaders, embeddings, and LLMs
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We use an OpenAI default embedding model
# Note the code in this example does not preserve privacy
embeddings = OpenAIEmbeddings()
# LangChain provides API functions to interact with FAISS
db = FAISS.from_documents(texts, embeddings)
# We create a 'retriever' that knows how to interact with our vector database using an augmented context
# We could construct the retriever ourselves from first principles but it's tedious
# Instead we'll use LangChain to create a retriever for our vector database
retriever = db.as_retriever()
from langchain.agents.agent_toolkits import create_retriever_tool
tool = create_retriever_tool(
retriever,
"search_state_of_union",
"Searches and returns documents regarding the state-of-the-union."
)
tools = [tool]
# We wrap an LLM (here OpenAI) with a conversational interface that can process augmented requests
from langchain.agents.agent_toolkits import create_conversational_retrieval_agent
# LangChain provides an API to interact with chat models
from langchain_openai.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature = 0)
agent_executor = create_conversational_retrieval_agent(llm, tools, verbose=True)
input = "what is NATO?"
result = agent_executor.invoke({“input": input})
# Response from the model
input = "When was it created?"
result = agent_executor.invoke({“input": input})
# Response from the model
 IDG
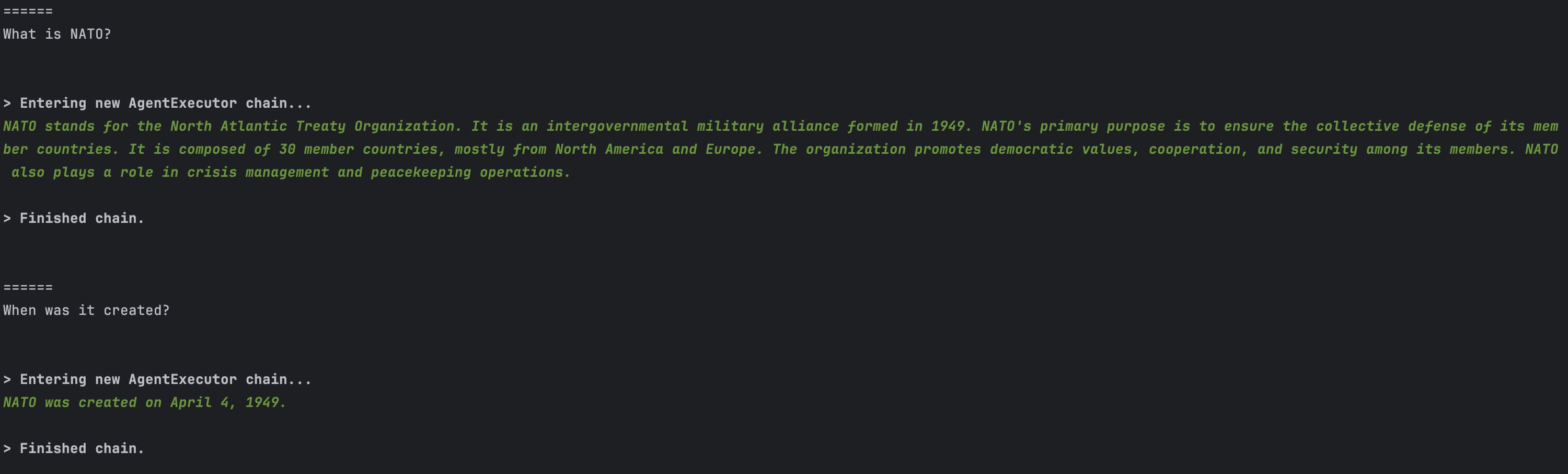
IDGAs shown in the screenshot above, the model’s response to our first question is quite accurate:
NATO stands for the North Atlantic Treaty Organization. It is an intergovernmental military alliance formed in 1949. NATO’s primary purpose is to ensure the collective defense of its member countries. It is composed of 30 member countries, mostly from North America and Europe. The organization promotes democratic values, cooperation, and security among its members. NATO also plays a crucial role in crisis management and peacekeeping operations around the world.
Finished chain.
And the model’s response to the second question is exactly right:
NATO was created on April 4, 1949.
Finished chain.
As we’ve seen, the use of a framework like LangChain greatly simplifies our first steps into LLM applications. LangChain is strongly recommended if you’re just starting out and you want to try some toy examples. It will help you get right to the meat of retrieval-augmented generation, meaning the document ingestion and the interactions between the vector database and the LLM, rather than getting stuck in the plumbing.
For scaling to a larger corpus and deploying a production application, a deeper dive into local LLMs, vector databases, and embeddings will be needed. Naturally, production deployments will involve much more nuance and customization, but the same principles apply. We will explore local LLMs, vector databases, and embeddings in more detail in future articles here.
Copyright © 2024 IDG Communications, Inc.








{kind=link}