In the beginning, there was a database. On the second day, there were many databases, all isolated silos… and then also data warehouses, data lakes, data marts, all different, and tools to extract, transform, and load all of the data we wanted a closer look at. Eventually, there was also metadata, data classification, data quality, data security, data lineage, data catalogs, and data meshes. And on the seventh day, as it were, Google dumped all of this on an unwitting reviewer, as Google Cloud Dataplex.
OK, that was a joke. This reviewer sort of knew what he was getting into, although he still found the sheer quantity of new information (about managing data) hard to take in.
Seriously, the distributed data problem is real. And so are the data security, safety of personally identifiable information (PII), and governance problems. Dataplex performs automatic data discovery and metadata harvesting, which allows you to logically unify your data without moving it.
Google Cloud Dataplex performs data management and governance using machine learning to classify data, organize data in domains, establish data quality, determine data lineage, and both manage and govern the data lifecycle. As we’ll discuss in more detail below, Dataplex typically starts with raw data in a data lake, does automatic schema harvesting, applies data validation checks, unifies the metadata, and makes data queryable by Google-native and open source tools.
Competitors to Google Cloud Dataplex include AWS Glue and Amazon EMR, Microsoft Azure HDInsight and Microsoft Purview Information Protection, Oracle Coherence, SAP Data Intelligence, and Talend Data Fabric.
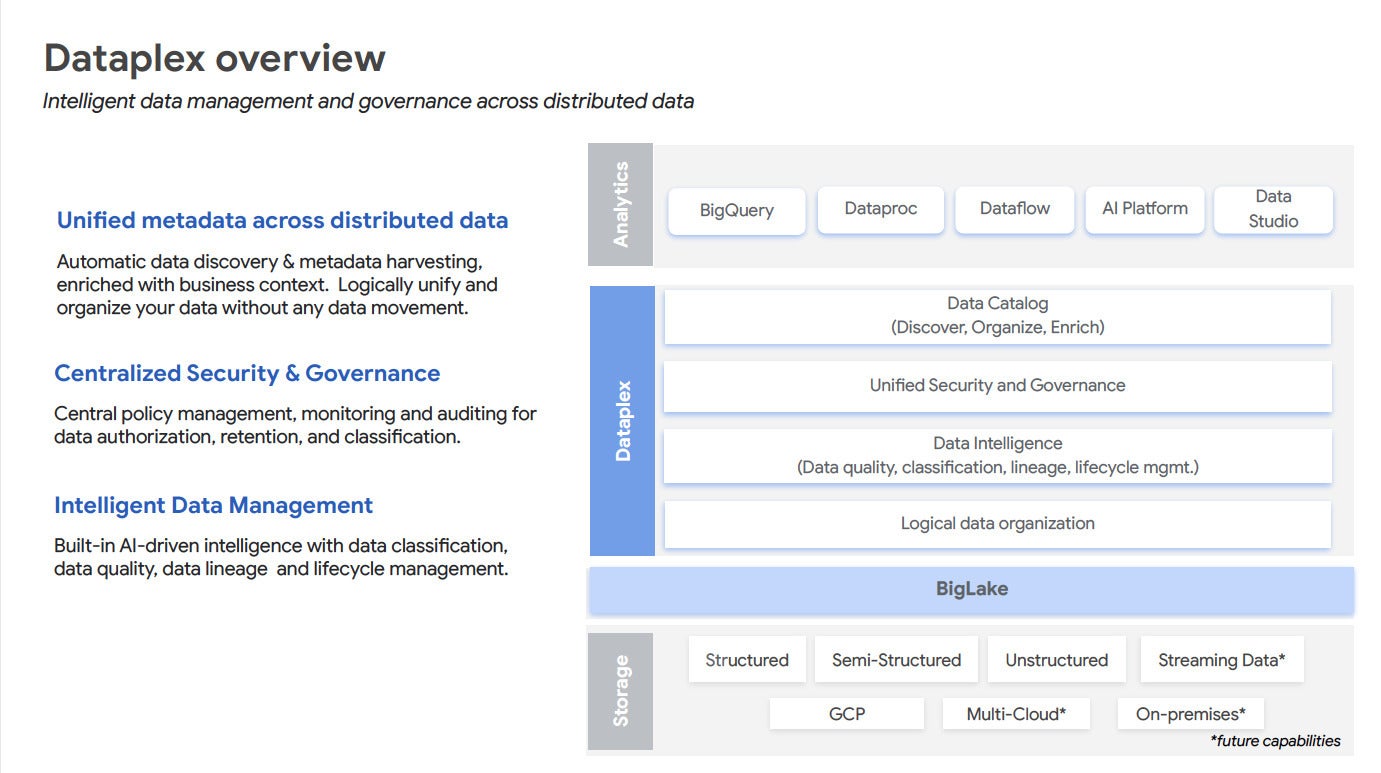 IDG
IDGGoogle Cloud Dataplex overview diagram. This diagram lists five Google analytics components, four functions of Dataplex proper, and seven kinds of data reachable via BigLake, of which three are planned for the future.
Google Cloud Dataplex features
Overall, Google Cloud Dataplex is designed to unify, discover, and classify your data from all of your data sources without requiring you to move or duplicate your data. The key to this is to extract the metadata that describes your data and store it in a central place. Dataplex’s key features:
Data discovery
You can use Google Cloud Dataplex to automate data discovery, classification, and metadata enrichment of structured, semi-structured, and unstructured data. You can manage technical, operational, and business metadata in a unified data catalog. You can search your data using a built-in faceted-search interface, the same search technology as Gmail.
Data organization and life cycle management
You can logically organize data that spans multiple storage services into business-specific domains using Dataplex lakes and data zones. You can manage, curate, tier, and archive your data easily.
Centralized security and governance
You can use Dataplex to enable central policy management, monitoring, and auditing for data authorization and classification, across data silos. You can facilitate distributed data ownership based on business domains with global monitoring and governance.
Built-in data quality and lineage
You can automate data quality across distributed data and enable access to data you can trust. You can use automatically captured data lineage to better understand your data, trace dependencies, and troubleshoot data issues.
Serverless data exploration
You can interactively query fully governed, high-quality data using a serverless data exploration workbench with access to Spark SQL scripts and Jupyter notebooks. You can collaborate across teams with built-in publishing, sharing, and search features, and operationalize your work with scheduling from the workbench.
How Google Cloud Dataplex works
As you identify new data sources, Dataplex harvests the metadata for both structured and unstructured data, using built-in data quality checks to enhance integrity. Dataplex automatically registers all metadata in a unified metastore. You can also access data and metadata through a variety of Google Cloud services, such as BigQuery, Dataproc Metastore, Data Catalog, and open source tools, such as Apache Spark and Presto.
The two most common use cases for Dataplex are a domain-centric data mesh and data tiering based on readiness. I went through a series of labs that demonstrate both.
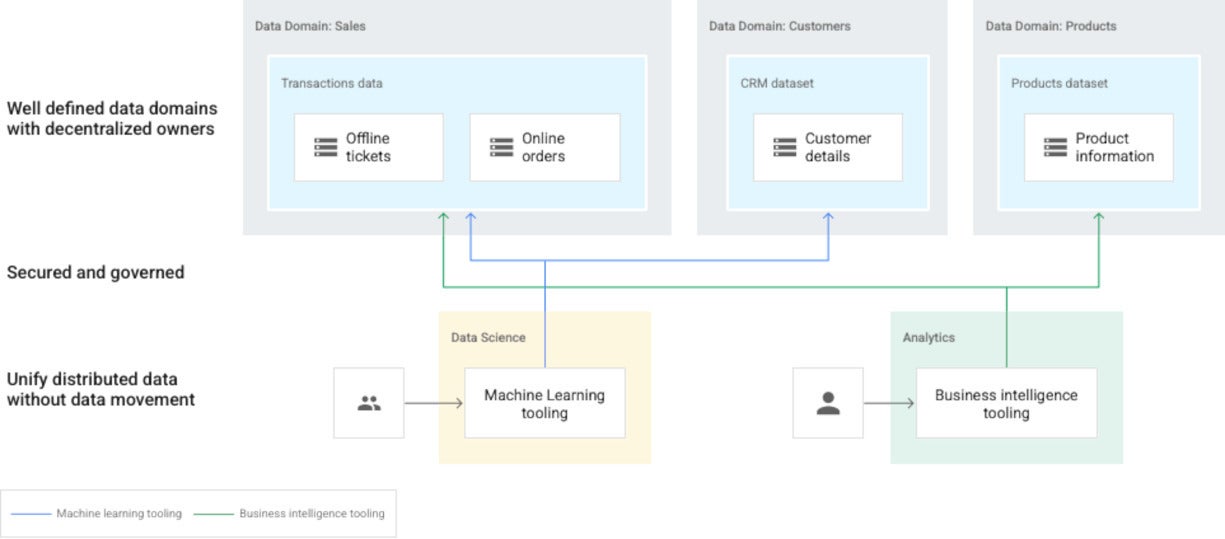 IDG
IDGIn this diagram, domains are represented by Dataplex lakes and owned by separate data producers. Data producers own creation, curation, and access control in their domains. Data consumers can then request access to the lakes (domains) or zones (sub-domains) for their analysis.
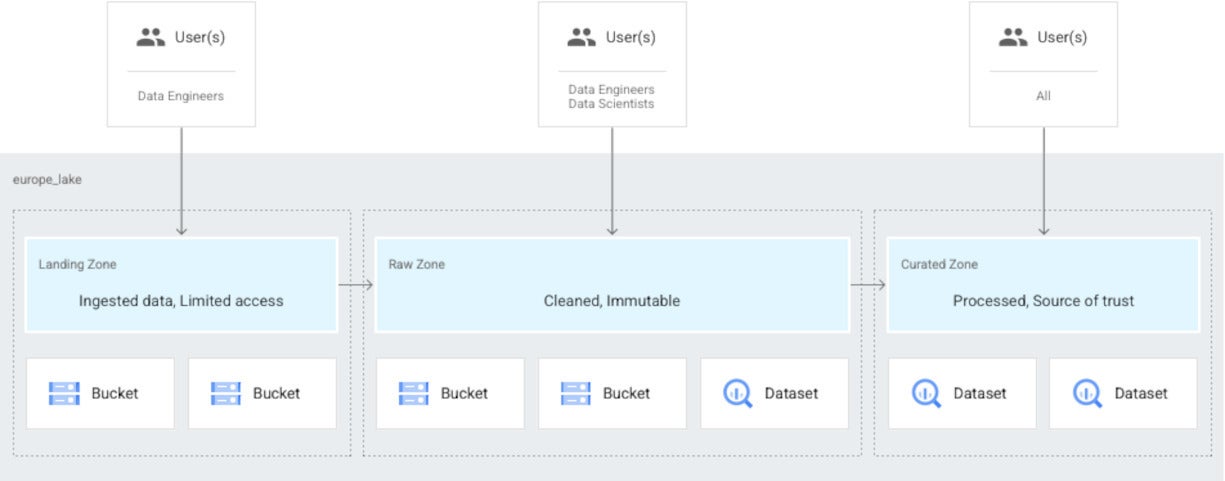 IDG
IDGData tiering means that your ingested data is initially accessible only to data engineers and is later refined and made available to data scientists and analysts. In this case, you can set up a lake to have a raw zone for the data that the engineers have access to, and a curated zone for the data that is available to the data scientists and analysts.
Preparing your data for analysis
Google Cloud Dataplex is about data engineering and conditioning, starting with raw data in data lakes. It uses a variety of tools to discover data and metadata, organize data into domains, enrich the data with business context, track data lineage, test data quality, curate the data, secure data and protect private information, monitor changes, and audit changes.
The Dataplex process flow starts in cloud storage with raw ingested data, often in CSV tables with header rows. The discovery process extracts the schema and does some curation, producing metadata tables as well as queryable files in cloud storage using Dataflow flex and serverless Spark jobs; the curated data can be in Parquet, Avro, or Orc format. The next step uses serverless Spark SQL to transform the data, apply data security, store it in BigQuery, and create views with different levels of authorization and access. The fourth step creates consumable data products in BigQuery that business analysts and data scientists can query and analyze.
 IDG
IDGGoogle Cloud Dataplex process flow. The data starts as raw CSV and/or JSON files in cloud storage buckets, then is curated into queryable Parquet, Avro, and/or ORC files using Dataflow flex and Spark. Spark SQL queries transform the data into refined BigQuery tables and secure and authorized views. Data profiling and Spark jobs bring the final data into a form that can be analyzed.
In the banking example that I worked through, the Dataplex data mesh architecture has four data lakes for different banking domains. Each domain has raw data, curated data, and data products. The data catalog and data quality framework are centralized.
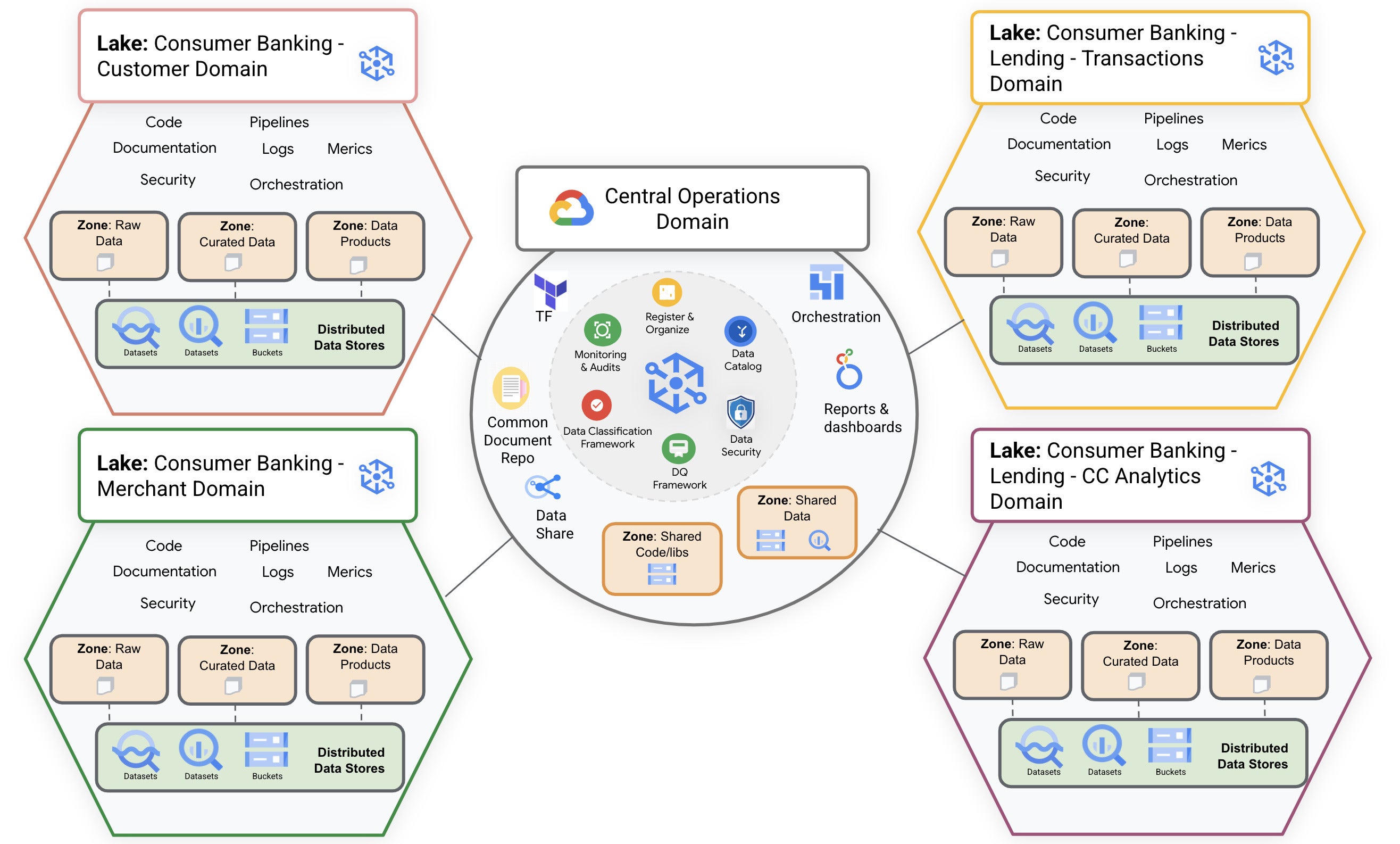 IDG
IDGGoogle Cloud Dataplex data mesh architecture. In this banking example, there are four domains in data lakes, for customer consumer banking, merchant consumer banking, lending consumer banking, and credit card consumer banking. Each data lake contains raw, curated, and product data zones. The central operations domain applies to all four data domains.
Automatic cataloging starts with schema harvesting and data validation checks, and creates unified metadata that makes data queryable. The Dataplex Attribute Store is an extensible infrastructure that lets you specify policy-related behaviors on the associated resources. That allows you to create taxonomies, create attributes and organize them in a hierarchy, associate one or more attributes to tables, and associate one or more attributes to columns.
You can track your data classification centrally and apply classification rules across domains to control the leakage of sensitive data such as social security numbers. Google calls this DLP (data loss prevention).
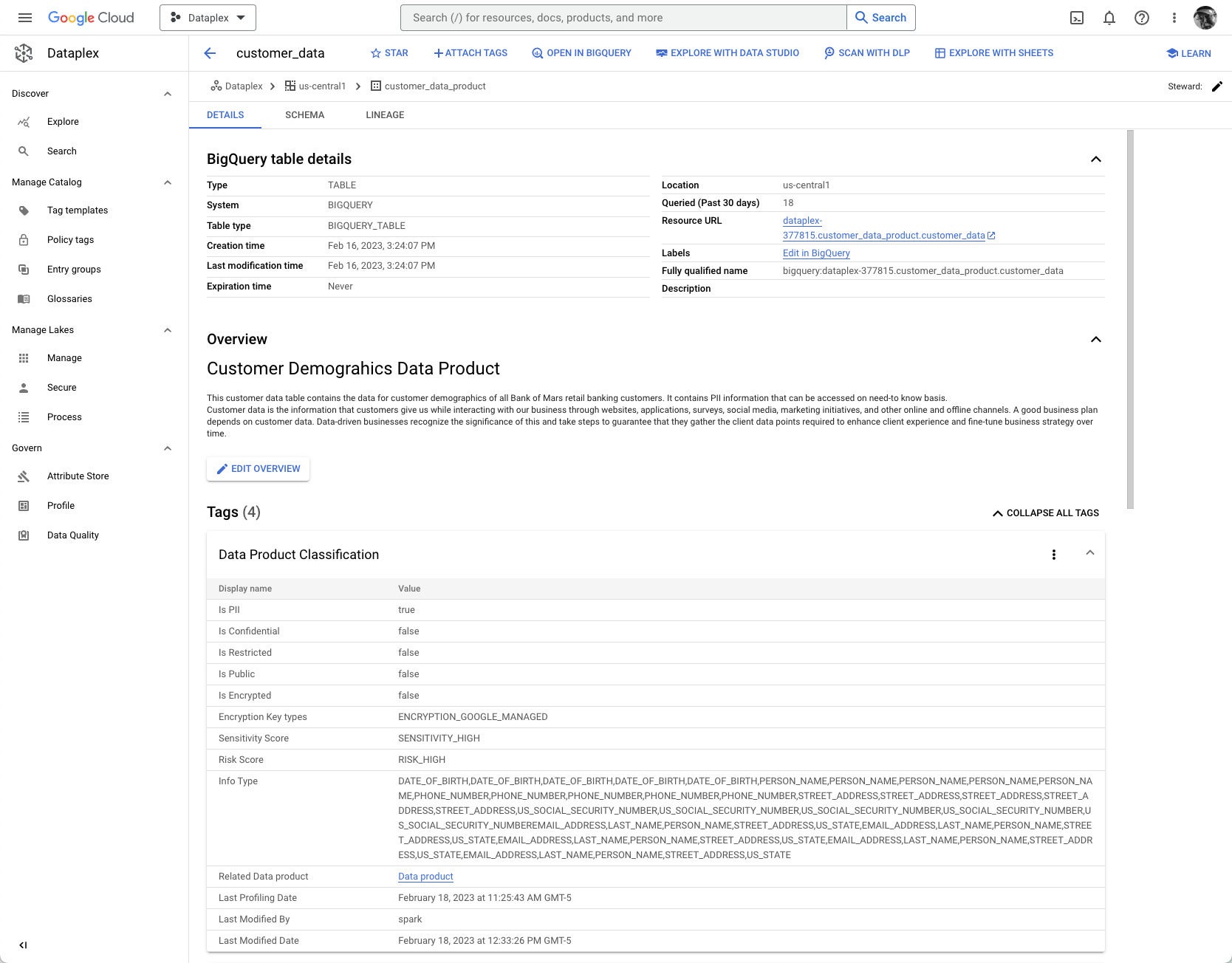 IDG
IDGCustomer demographics data product. At this level information that is PII (personally identifiable information) or otherwise sensitive can be flagged, and measures can be taken to reduce the risk, such as masking sensitive columns from unauthorized viewers.
Automatic data profiling, currently in public preview, lets you identify common statistical characteristics of the columns of your BigQuery tables within Dataplex data lakes. Automatic data profiling performs scans to let you see the distribution of values for individual columns.
End-to-end data lineage helps you to understand the origin of your data and the transformations that have been applied to it. Among other benefits, data lineage allows you to trace the downstream impact of data issues and identify the upstream causes.
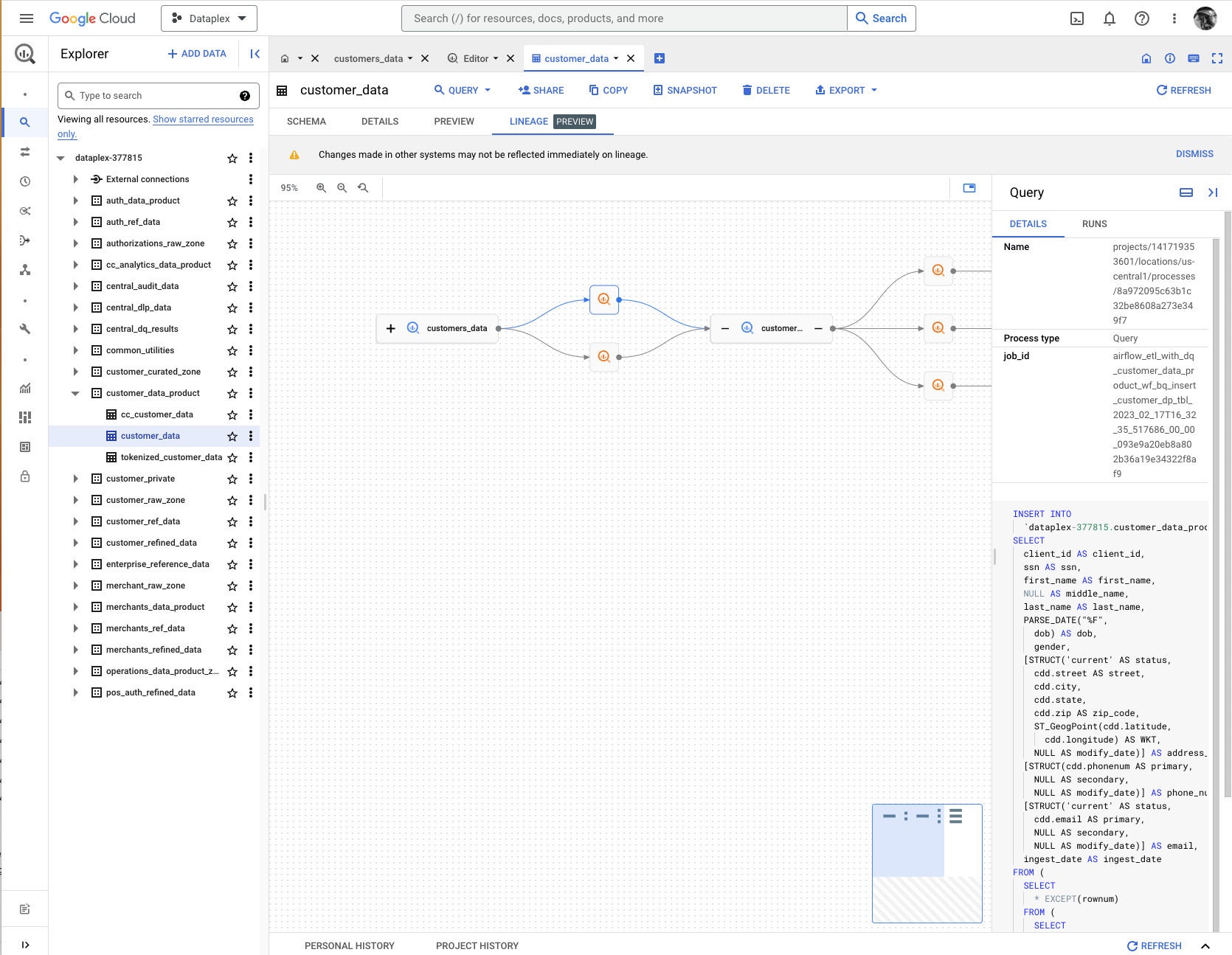 IDG
IDGGoogle Cloud Dataplex explorer data lineage. Here we are examining the SQL query that underlies one step in the data transformation process. This particular query was run as an Airflow DAG from Google Cloud Composer.
Dataplex’s data quality scans apply auto-recommended rules to your data, based on the data profile. The rules screen for common issues such as null values, values (such as IDs) that should be unique but aren’t, and values that are out of range, such as birth dates that are in the future or the distant past.
I half-joked at the beginning of this review about finding Google Cloud Dataplex somewhat overwhelming. It’s true, it is overwhelming. At the same time, Dataplex seems to be potentially the most complete system I’ve seen for turning raw data from silos into checked and governed unified data products ready for analysis.
Google Cloud Dataplex is still in preview. Some of its components are not in their final form, and others are still missing. Among the missing are connections to on-prem storage, streaming data, and multi-cloud data. Even in preview form, however, Dataplex is highly useful for data engineering.
Vendor: Google, https://cloud.google.com/dataplex
Cost: Based on pay-as-you-go usage; $0.060/DCU-hour standard, $0.089/DCU-hour premium, $0.040/DCU-hour shuffle storage.
Platform: Google Cloud Platform.
Copyright © 2023 IDG Communications, Inc.








{kind=link}