The new release of Steampipe is all about relationship graphs. Our blog post shows how these graphs provide contextual awareness for devops and security pros who can now see all the resources related to an EC2 instance, or determine at a glance whether the permissions related to an IAM role are properly scoped. As always, developers can explore and remix the code that builds these graphs, and adapt the idioms for their own purposes in any data domain.
These relationship graphs are driven by SQL queries that define nodes and edges. Such queries can use any column of any table provided by any Steampipe plugin to form nodes, and then edges between nodes. If you want to see connections among the people and objects represented by diverse APIs, you can now use SQL idioms to graph them. The only limit is your imagination.
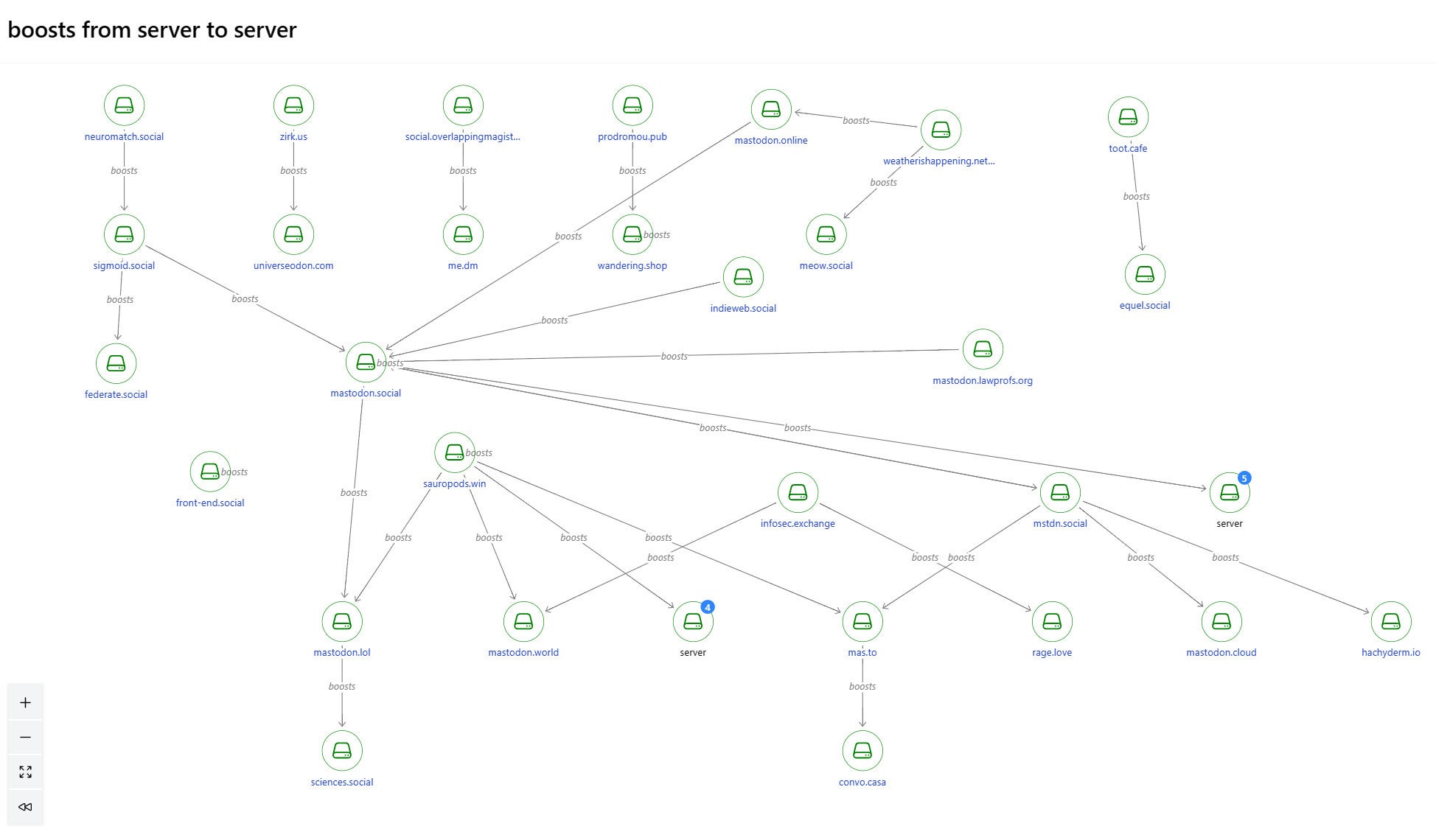
Naturally I imagined graphing Mastodon relationships. So far I’ve built two graphs that visualize my home timeline. Here’s the first one.
 IDG
IDGHere we’re looking at the most recent 50 boosts (the Mastodon version of retweet) in my homeline. This is the query to find them.
select
*
from
mastodon_toot
where
timeline="home"
and reblog_server is not null
limit 50
If we focus on Brian Marick we can see that:
- Brian belongs to mastdn.social.
- Brian boosted a post by Tim Bray.
- Tim belongs to hachyderm.io.
So this graph shows people on a selected server boosting people on other servers. In this case mastdn.social is the selected server, but we can refocus the graph on any other server that’s sending boosts.
The second graph zooms out to show the web of boost relationships among servers. If anyone on infosec.exchange boosts anyone on mastodon.world, there’s an edge connecting the two nodes. Although it’s not happening anywhere in this graph, the arrow can point both ways and would if anyone on mastodon.world were also boosting anyone on infosec.exchange.
 IDG
IDGLet’s build up the first graph step by step.
Step 1: Identify the selected server
Here’s the definition of the node that represents the selected server.
node {
category = category.selected_server
args = [ self.input.server.value ]
sql = <<EOQ
select
server as id,
server as title,
jsonb_build_object(
'server', server
) as properties
from
mastodon_boosts()
where
server = $1
EOQ
}
Per the documentation, a node’s query must at least select a column aliased as id. Here it’s the server column in a row returned by the above query. I’ve packaged that query into a SQL function, mastodon_boosts, to hide details (timeline="home" reblog_server is not null limit 50) and make it easier to focus on what’s special about each node. In this case the special quality is that the server column that gives the node its identity matches the selected server.
If the graph block includes only this node, and mastdn.social is the selected server, here is the rendering. Not much to see here yet!
 IDG
IDGThe node defines a bag of properties that can be any of the columns returned by the underlying query; these appear when you hover the node. The node also refers to a category that governs the node’s icon, color, and link. Here’s the category for the selected server.
category "selected_server" {
color = "darkgreen"
icon = "server"
href = "https://{{.properties.'server'}}"
}
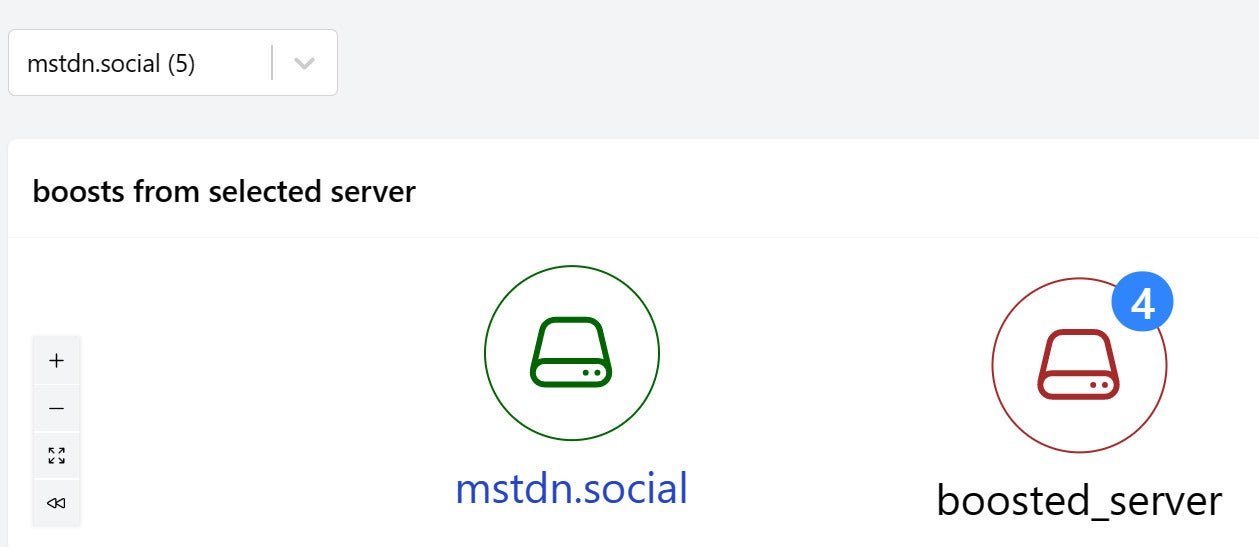
Step 2: Identify boosted servers
Now we’ll add boosted servers. This node uses the same set of records: the 50 most recent boosts in my feed. Again it finds just those whose server column matches the selected server. But the id is now the reblog_server which is the target, instead of the origin, of boosts from the selected server.
node {
category = category.boosted_server
args = [ self.input.server.value ]
sql = <<EOQ
select
reblog_server as id,
reblog_server as title
from
mastodon_boosts()
where
server = $1
EOQ
}
Here’s the graph with both selected_server and boosted_server nodes. We’ve used another category to differentiate the boosted nodes.
 IDG
IDGThere’s only one selected server but it can send boosts to more than one boosted server. The default rendering folds them into one node but you can click to unfold and see all of them.
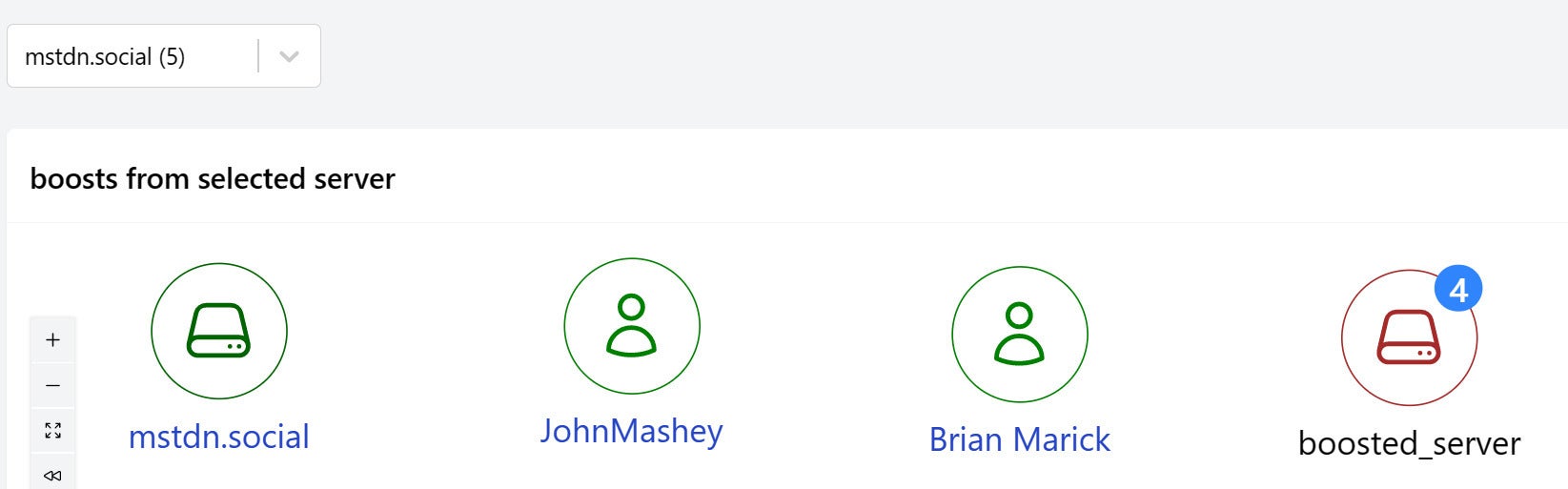
Step 3: Identify people who boost others
Where are the people? Let’s add them next, starting with the people who are sending boosts.
node {
category = category.person
args = [ self.input.server.value ]
sql = <<EOQ
select
username as id,
display_name as title,
jsonb_build_object(
'instance_qualified_account_url', instance_qualified_account_url
) as properties
from
mastodon_boosts()
where
server = $1
EOQ
}
 IDG
IDGThe username column gives the node its identity. Note also the property instance_qualified_account_url. That’s the synthetic column we added to the Mastodon plugin last time to ensure that links to people and toots will work properly in the Mastodon client. Because it’s included in a property here, and because category.person refers to that property, links representing people in the graph will resolve properly.
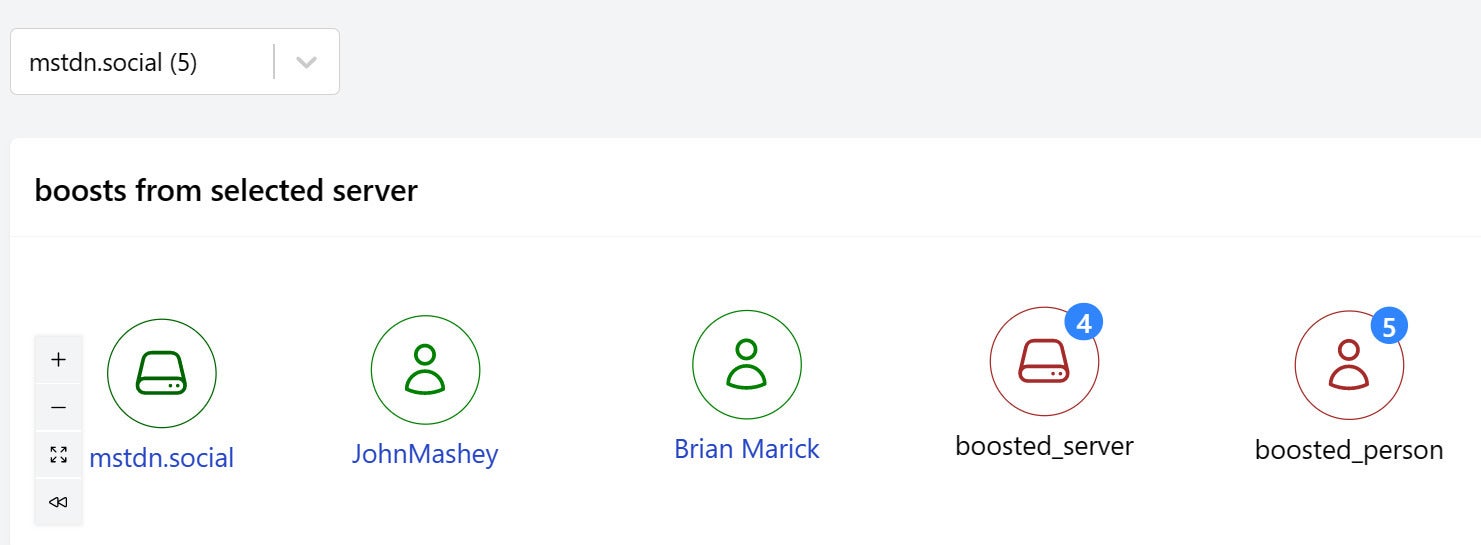
Step 4: Identify people who are boosted
This node takes its identify from the reblog_username column, and uses the synthetic column instance_qualified_reblog_url to provide the link.
node {
category = category.boosted_person
args = [ self.input.server.value ]
sql = <<EOQ
select
reblog_username as id,
reblog_username as title,
jsonb_build_object(
'instance_qualified_reblog_url', instance_qualified_reblog_url
) as properties
from
mastodon_boosts()
where
server = $1
EOQ
}
 IDG
IDGStep 5: Connect boosters on the selected server to that server
So far we’ve seen only nodes, whose queries minimally return the id property. An edge connects nodes by way of a query that minimally returns columns aliased to from_id and to_id.
edge {
sql = <<EOQ
select
username as from_id,
server as to_id,
'belongs to' as title
from
mastodon_boosts()
EOQ
}
You’ll also want to provide a title to label the edge. Here this edge occurs twice to represent “John Mashey belongs to mstdn.social” and “Brian Marick belongs to mstdn.social.”
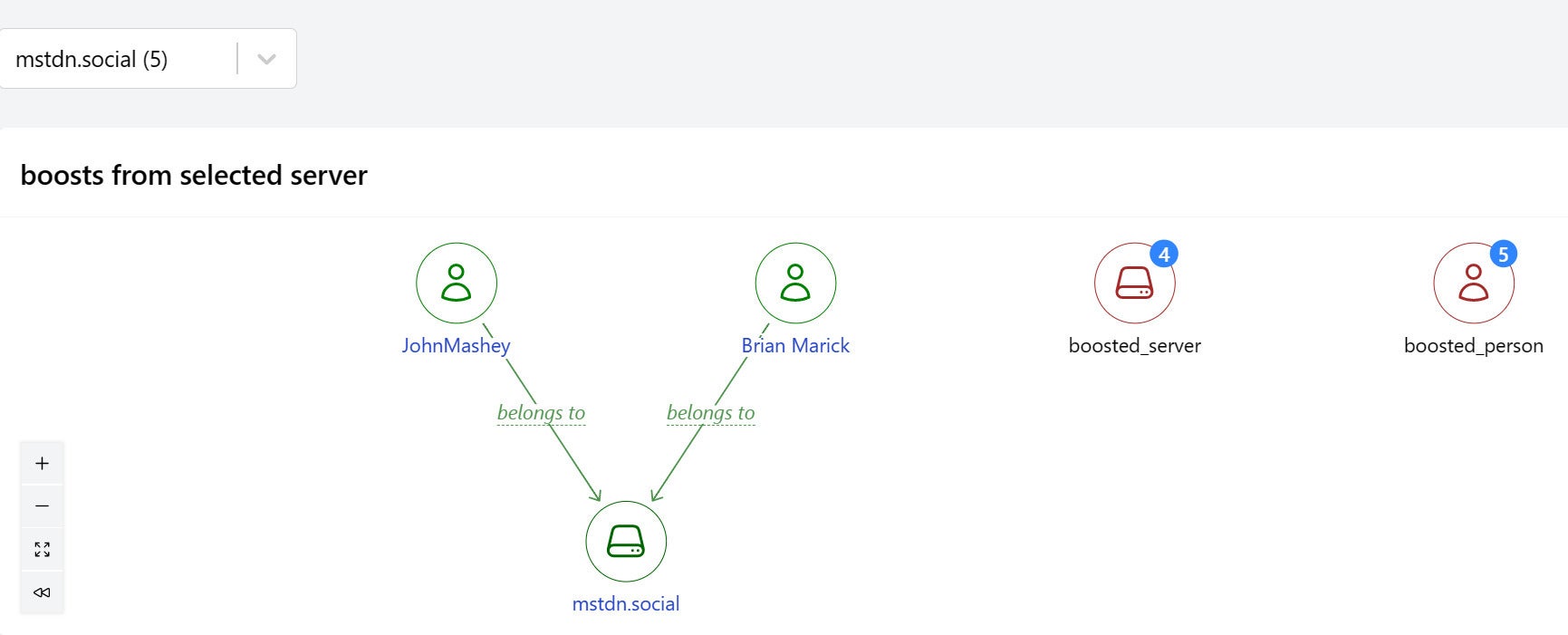 IDG
IDGStep 6: Connect people on boosted servers to their servers
This edge works the same way, but captures the relationship between boosted people and their servers.
edge {
args = [ self.input.server.value ]
sql = <<EOQ
select
reblog_username as from_id,
reblog_server as to_id,
'belongs to' as title
from
mastodon_boosts()
where
server = $1
EOQ
}
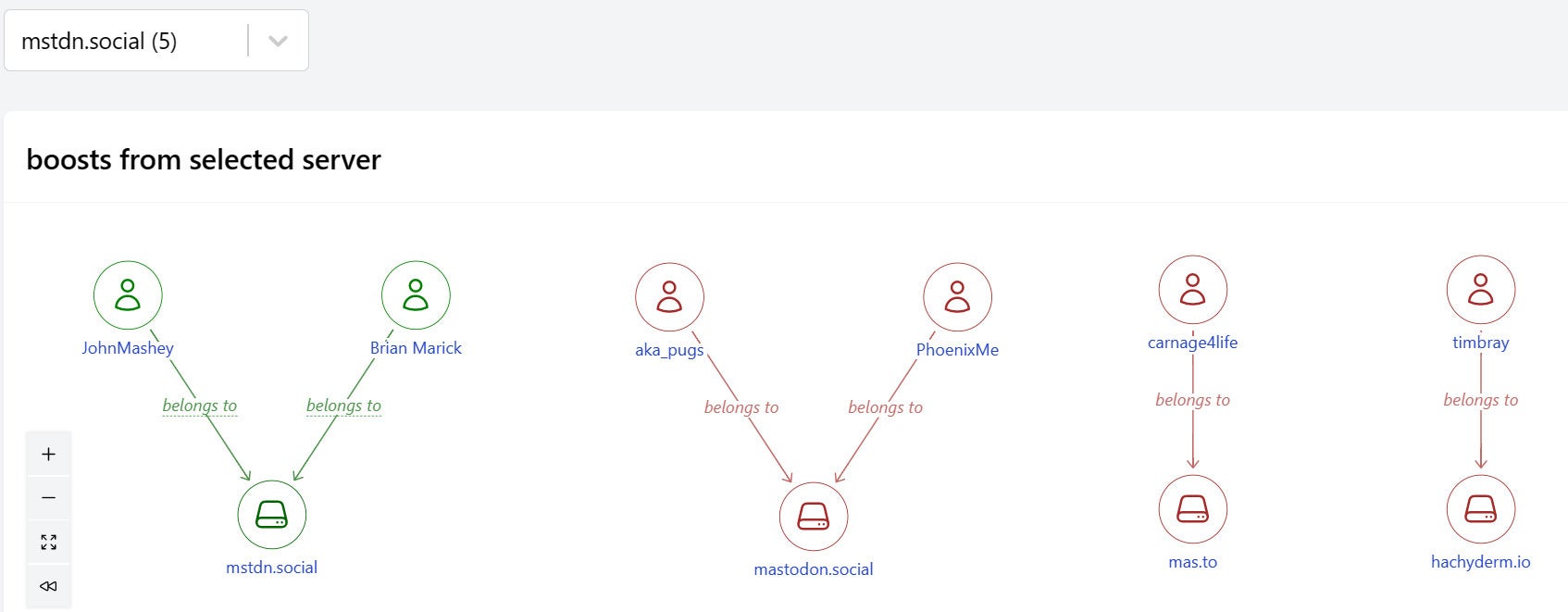 IDG
IDGStep 7: Connect boosters to the people they boost
Finally we add an edge to connect boosters to the people they boost.
edge {
category = category.boost
args = [ self.input.server.value ]
sql = <<EOQ
select
username as from_id,
reblog_username as to_id,
'boosts' as title,
jsonb_build_object(
'reblog_username', reblog_username,
'reblog_server', reblog_server,
'content', reblog ->> 'content'
) as properties
from
mastodon_boosts()
where
server = $1
EOQ
}
And now we’ve completed the first graph shown above.
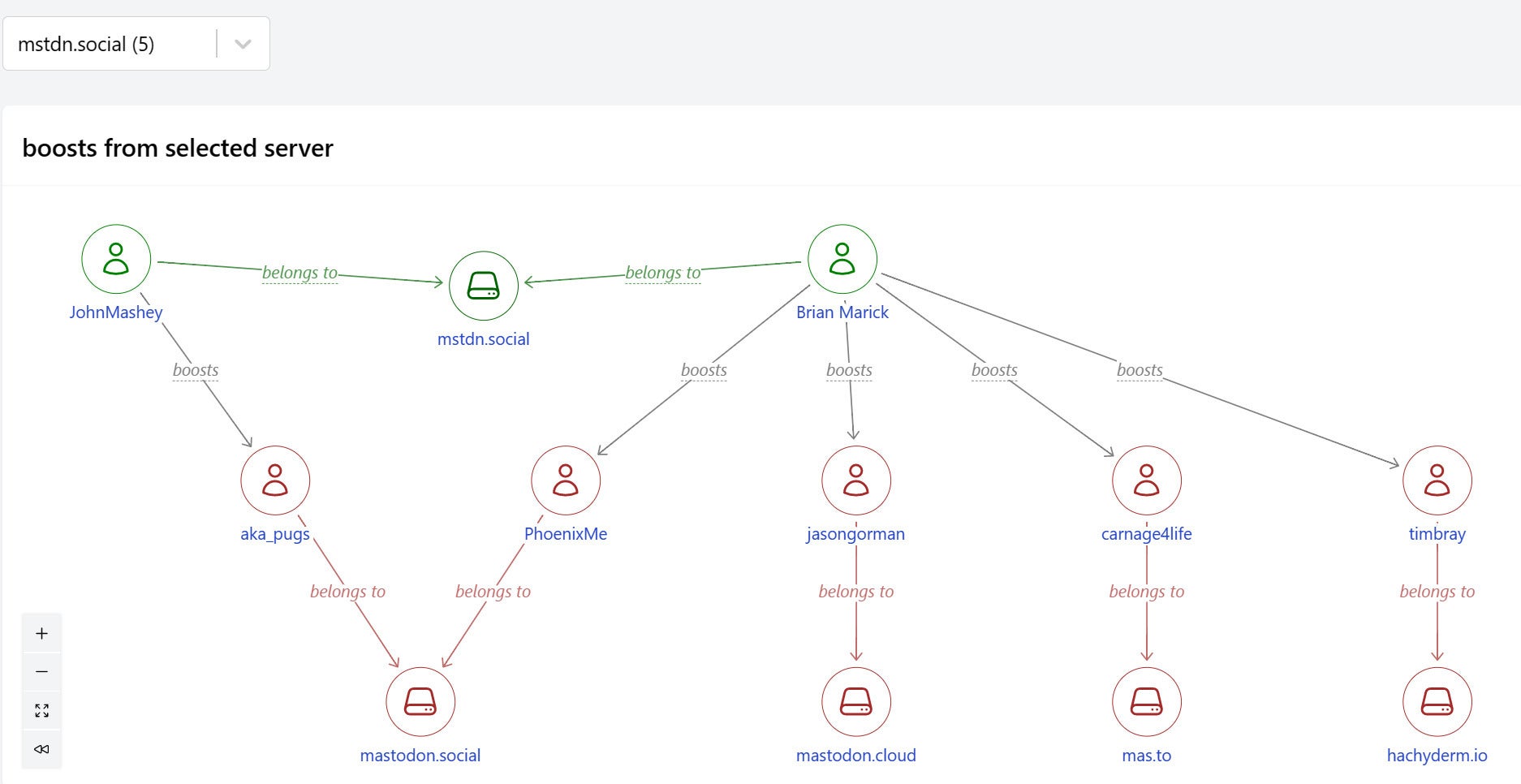 IDG
IDGGraphing GitHub relationships
You can use this grammar of nodes and edges to describe relationships in any domain. Here’s a graph that looks across all the Steampipe-related repos and shows recently-updated PRs from external contributors.
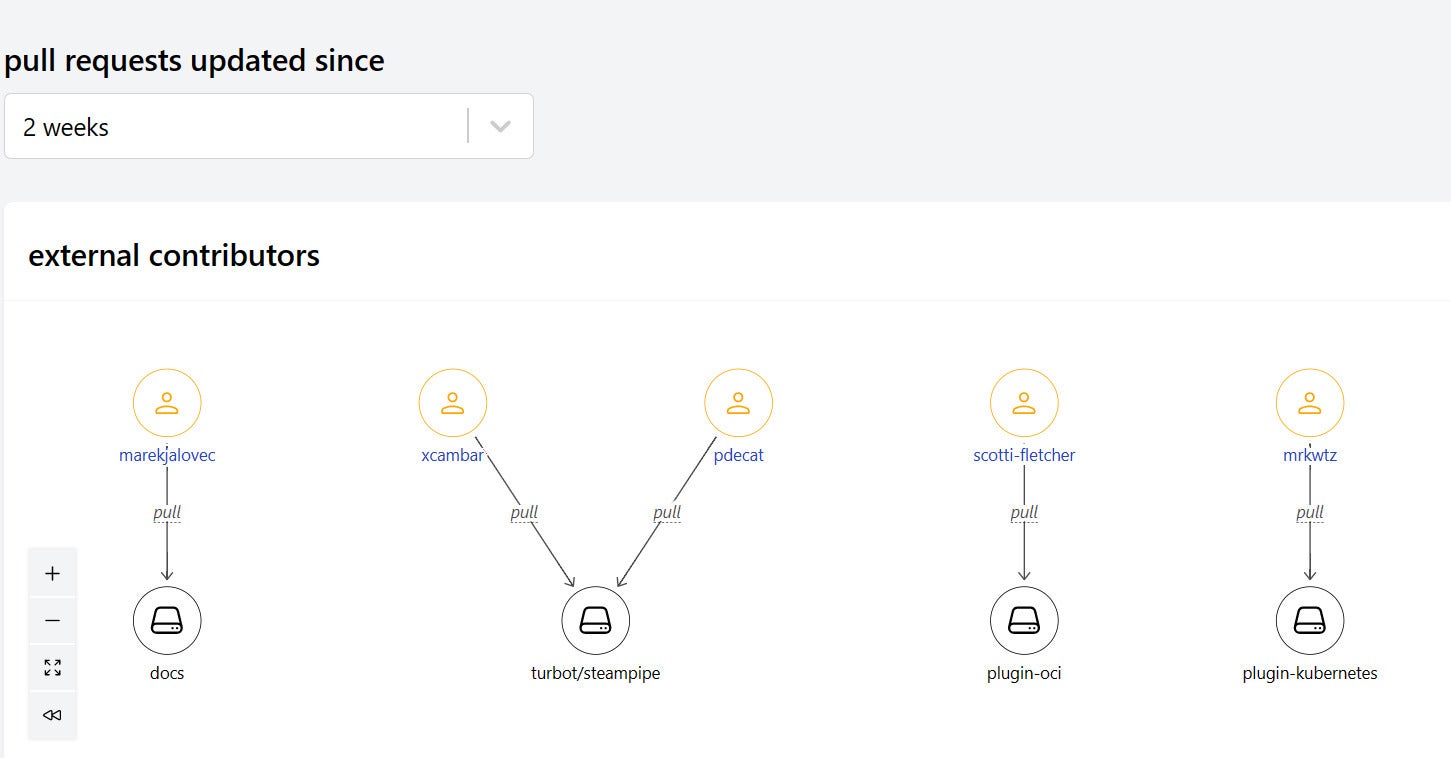 IDG
IDGAnd here’s one that uses any Steampipe plugin to show recently-updated pull requests for a selected repo.
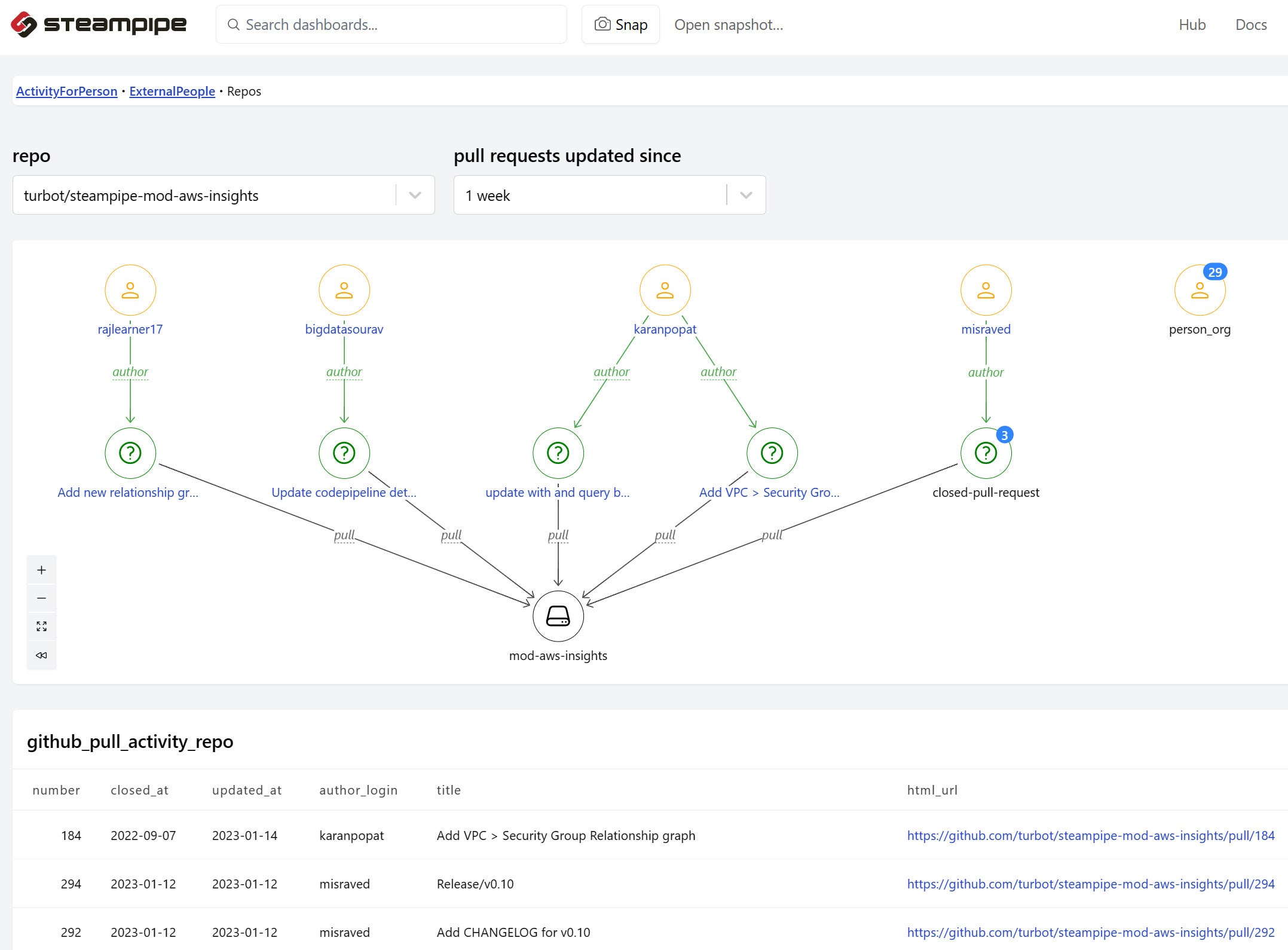 IDG
IDGThese two views share a common SQL query and serve complementary purposes. The table is handy for sorting by date or author, the graph highlights one-to-many relationships.
Lifting the burden of context assembly
In What TimeDance got right I mourned the passing of a tool for scheduling meetings that had excelled at bringing together the messages and documents related to a meeting. I called this “context assembly” — a term I’d picked up from Jack Ozzie, cofounder of Groove, another collaboration tool whose passing I mourn. Context assembly is hard work. Too often the burden falls on people who only need to use that context and would rather not spend time and effort creating it.
We’ve seen how SQL can unify access to APIs. Now it can also help us see relationships among the data we extract from those APIs.
See also:
Copyright © 2023 IDG Communications, Inc.








{kind=link}