Large language models (LLMs), the algorithmic platforms on which generative AI (genAI) tools like ChatGPT are built, are highly inaccurate when connected to corporate databases and becoming less transparent, according to two studies.
One study by Stanford University showed that as LLMs continue to ingest massive amounts of information and grow in size, the genesis of the data they use is becoming harder to track down. That, in turn, makes it difficult for businesses to know whether they can safely build applications that use commercial genAI foundation models and for academics to rely on them for research.
It also makes it more difficult for lawmakers to design meaningful policies to rein in the powerful technology, and “for consumers to understand model limitations or seek redress for harms caused,” the Stanford study said.
LLMs (also known as foundation models) such as GPT, LLaMA, and DALL-E emerged over the past year and have transformed artificial intelligence (AI), giving many of the companies experimenting with them a boost in productivity and efficiency. But those benefits come with a heavy dollop of uncertainty.
“Transparency is an essential precondition for public accountability, scientific innovation, and effective governance of digital technologies,” said Rishi Bommasani, society lead at Stanford’s Center for Research on Foundation Models. “A lack of transparency has long been a problem for consumers of digital technologies.”
 Stanford University
Stanford UniversityFor example, deceptive online ads and pricing, unclear wage practices in ride-sharing, dark patterns that trick users into unknowing purchases, and a myriad number of transparency issues around content moderation created a vast ecosystem of mis- and disinformation on social media, Bommasani noted.
“As transparency around commercial [foundation models] wanes, we face similar sorts of threats to consumer protection,” he said.
For example, OpenAI, which has the word “open” right in its name, has clearly stated that it will not be transparent about most aspects of its flagship model, GPT-4, the Stanford researchers noted.
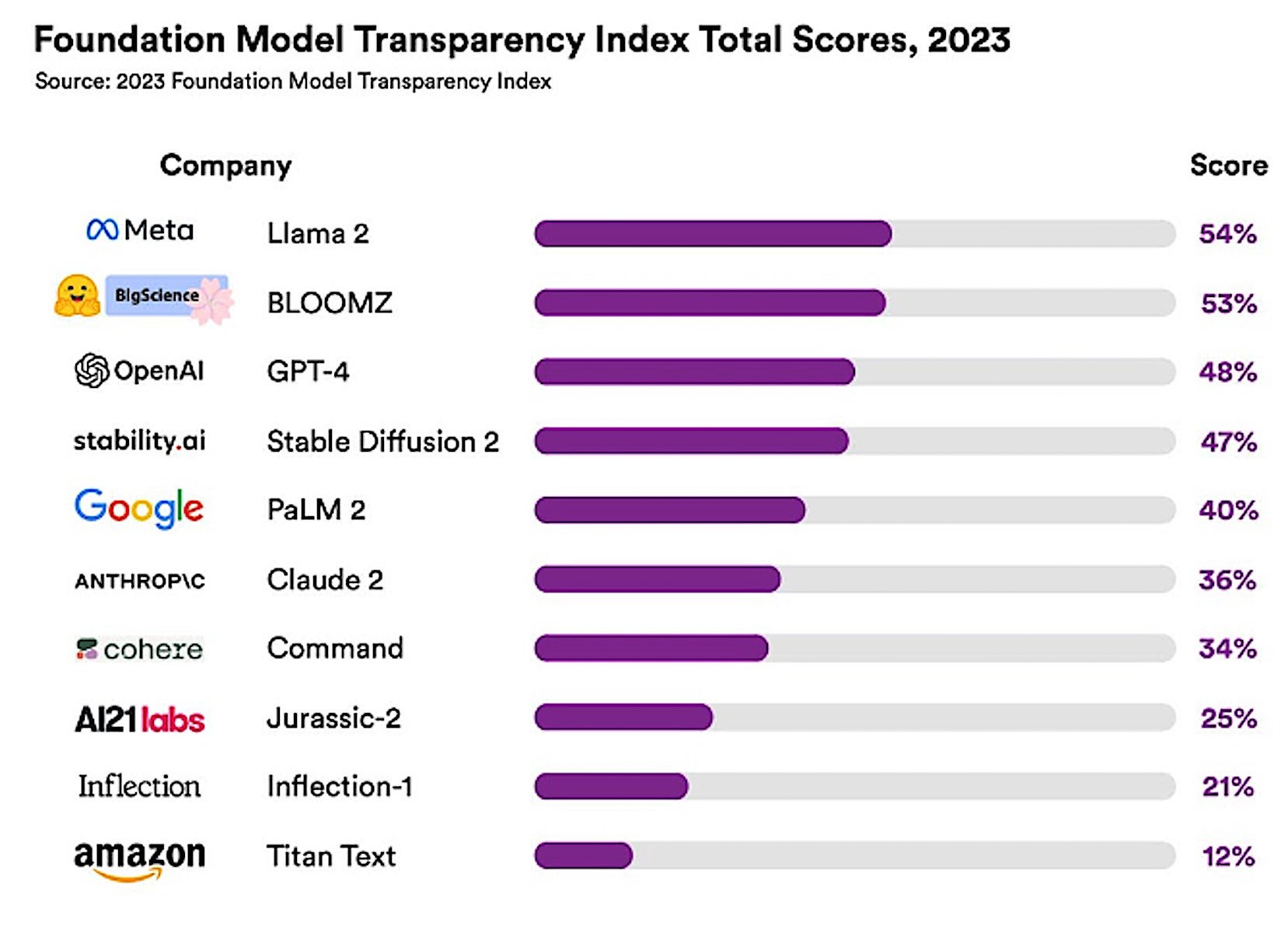
To assess transparency, Stanford brought together a team that included researchers from MIT and Princeton to design a scoring system called the Foundation Model Transparency Index (FMTI). It evaluates 100 different aspects or indicators of transparency, including how a company builds a foundation model, how it works, and how it is used downstream.
The Stanford study evaluated 10 LLMs and found the mean transparency score was just 37%. LLaMA scored highest, with a transparency rating of 52%; it was followed by GPT-4 and PaLM 2, which scored 48% and 47%, respectively.
“If you don’t have transparency, regulators can’t even pose the right questions, let alone take action in these areas,” Bommasani said.
Meanwhile, almost all senior bosses (95%) believe genAI tools are regularly used by employees, with more than half (53%) saying it is now driving certain business departments, according to a separate survey by cybersecurity and antivirus provider Kaspersky Lab. That study found 59% of executives now expressing deep concerns about genAI-related security risks that could jeopardize sensitive company information and lead to a loss of control of core business functions.
“Much like BYOD, genAI offers massive productivity benefits to businesses, but while our findings reveal that boardroom executives are clearly acknowledging its presence in their organizations, the extent of its use and purpose are shrouded in mystery,” David Emm, Kaspersky’s principal security researcher, said in a statement.
The problem with LLMs goes deeper than just transparency; the overall accuracy of the models has been questioned almost from the moment OpenAI released ChatGPT a year ago.
Juan Sequeda, head of the AI Lab at data.world, a data cataloging platform provider, said his company tested LLMs connected to SQL databases and tasked with providing answers to company-specific questions. Using real-world insurance company data, data.world’s study showed that LLMs return accurate responses to most basic business queries just 22% of the time. And for intermediate and expert-level queries, accuracy plummeted to 0%.
The absence of suitable text-to-SQL benchmarks tailored to enterprise settings may be affecting LLMs’ ability to accurately respond to user questions or “prompts.”
“It’s understood that LLMs lack internal business context, which is key to accuracy,” Sequeda said. “Our study shows a gap when it comes to using LLMs specifically with SQL databases, which is the main source of structured data in the enterprise. I would hypothesize that the gap exists for other databases as well.”
Enterprises invest millions of dollars in cloud data warehouses, business intelligence, visualization tools, and ETL and ELT systems, all so they can better leverage data, Sequeda noted. Being able to use LLMs to ask questions about that data opens up huge possibilities for improving processes such as key performance indicators, metrics and strategic planning, or creating entirely new applications that leverage the deep domain expertise to create more value.
The study primarily focused on question answering using GPT-4, with zero-shot prompts directly on SQL databases. The accuracy rate? Just 16%.
The net effect of inaccurate responses based on corporate databases is an erosion of trust. “What happens if you are presenting to the board with numbers that aren’t accurate? Or the SEC? In each instance, the cost would be high,” Sequeda said.
The problem with LLMs is that they are statistical and pattern-matching machines that predict the next word based on what words have come before. Their predictions are based on observing patterns from the entire content of the open web. Because the open web is essentially a very large dataset, the LLM will return things that seem very plausible but may also be inaccurate, according to Sequeda.
“A subsequent reason is that the models only make predictions based on the patterns they have seen. What happens if they haven’t seen patterns specific to your enterprise? Well, the inaccuracy increases,” he said.
“If enterprises try to implement LLMs at any significant scale without addressing accuracy, the initiatives will fail,” Sequeda continued. “Users will soon discover that they can’t trust the LLMs and stop using them. We’ve seen a similar pattern in data and analytics over the years.”
The accuracy of LLMs increased to 54% when questions are posed over a Knowledge Graph representation of the enterprise SQL database. “Therefore, investing in Knowledge Graph providers higher accuracy for LLM-powered questions-answering systems,” Sequeda said. “It’s still not clear why this happens, because we don’t know what’s going on inside the LLM.
“What we do know is that if you give an LLM a prompt with the ontology mapped within a knowledge graph, which contains the critical business context, the accuracy is three times more than if you don’t,” Sequeda continued. “However, it’s important to ask ourselves, what does ‘accurate enough’ mean?”
To increase the possibility of accurate responses from LLMs, companies need to have a “strong data foundation,” or what Sequeda and others call AI-ready data; that means the data is mapped in a Knowledge Graph to increase the accuracy of the responses and to ensure that there is explainability, “which means that you can make the LLM show its work.”
Another way to boost model accuracy would be using small language models (SLMs) or even industry-specific language models (ILMs). “I could see a future where each enterprise is leveraging a number of specific LLMs, each tuned for specific types of question-answering,” Sequeda said.
“Nevertheless, the approach continues to be the same: predicting the next word. That prediction may be high, but there will always be a chance that the prediction is wrong.”
Every company also needs to ensure oversight and governance to prevent sensitive and proprietary information from being placed at risk by models that aren’t predictable, Sequeda said.
Copyright © 2023 IDG Communications, Inc.








{kind=link}