In the previous installment of this series, we delved into the intricacies of the PaLM API and its seamless integration with LangChain. The great advantage of LangChain is the flexibility to swap out the large language model (LLM) with only slight changes to our code. As we have seen, within the LangChain framework, the LLM is transformed into a simple “link” in the chain, facilitating straightforward replacements.
LangChain supports a variety of use cases including summarization, question answering, sentiment analysis, and more. While the last tutorial explored the basics of LangChain and the Google PaLM API, this article will look at extracting answers from a PDF through the combination of the LangChain SDK and the PaLM API.
Let’s get started.
Download the PDF
Make a directory named data and download the PDF of Joe Biden’s 2023 State of the Union address from the EU parliament website.
wget -O data/sotu.pdf https://www.europarl.europa.eu/RegData/etudes/ATAG/2023/739359/EPRS_ATA(2023)739359_EN.pdf
We will use the data in this PDF to build our Q&A app.
Import Python modules
Start by importing the Python modules listed below.
from langchain.llms import GooglePalm from langchain.embeddings import GooglePalmEmbeddings from langchain.text_splitter import CharacterTextSplitter from langchain.vectorstores import FAISS from langchain.document_loaders import PyPDFLoader from langchain.chains.question_answering import load_qa_chain
Load the document with PyPDFLoader.
loader = PyPDFLoader ("./data/sotu.pdf")
documents = loader.load()
Convert the content into raw text.
raw_text=""
for i, doc in enumerate(documents):
text = doc.page_content
if text:
raw_text += text
Create chunks of text
We will then create chunks of 200 characters from the raw text. This helps speed up the queries by loading smaller chunks of relevant data.
text_splitter = CharacterTextSplitter( separator = "\n", chunk_size = 200, chunk_overlap = 40, length_function = len, ) texts = text_splitter.split_text(raw_text)
Generate embeddings
Let’s set the text embeddings model to Google PaLM.
embeddings = GooglePalmEmbeddings()
We are now ready to generate the embeddings for all the chunks of text we created.
docsearch = FAISS.from_texts(texts, embeddings)
FAISS (Facebook AI Similarity Search) is a popular library from Facebook for performing in-memory similarity searches. Since our document is small, we can rely on this library. For larger documents, using a vector database is recommended.
Create a Q&A chain
We will now create a Q&A chain that will be passed on to the PaLM model.
chain = load_qa_chain(GooglePalm(), chain_type="stuff")
The process of the “stuff” document chain is straightforward. It involves compiling a list of documents, inputting them into a prompt, and then submitting that prompt to an LLM. This process is useful when dealing with a small number of documents that are not too extensive.
It’s time to fire up the first question.
query = "Explain who created the document and what is the purpose?" docs = docsearch.similarity_search(query) print(chain.run(input_documents=docs, question=query).strip())
 IDG
IDGThe answer seems on target. I tested this model with a few more questions.
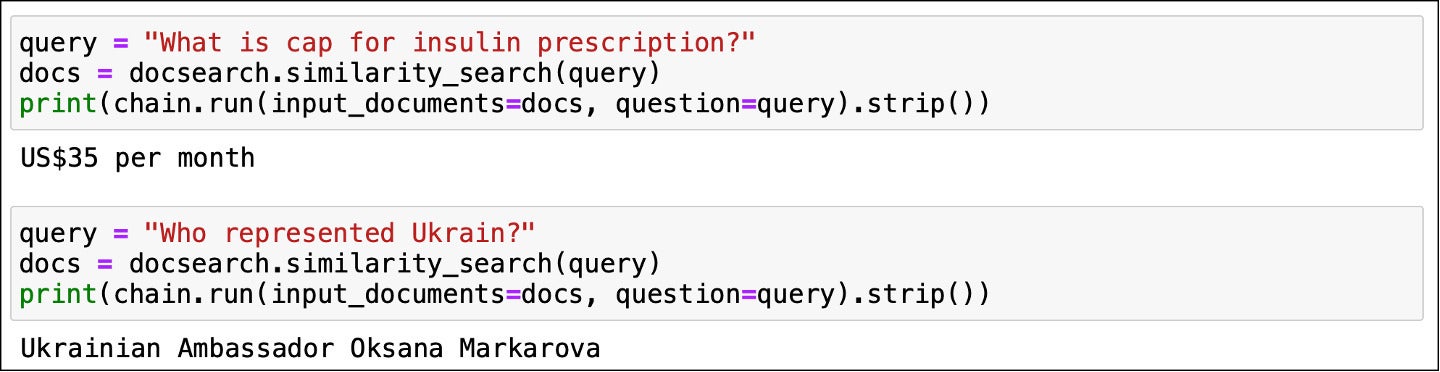 IDG
IDGComplete PaLM 2 Q&A example
Below is the complete code you can run in your own environment or in Google Colab.
from langchain.llms import GooglePalm
from langchain.embeddings import GooglePalmEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
from langchain.chains.question_answering import load_qa_chain
loader = PyPDFLoader ("./data/sotu.pdf")
documents = loader.load()
raw_text=""
for i, doc in enumerate(documents):
text = doc.page_content
if text:
raw_text += text
text_splitter = CharacterTextSplitter(
separator = "\n",
chunk_size = 200,
chunk_overlap = 40,
length_function = len,
)
texts = text_splitter.split_text(raw_text)
embeddings = GooglePalmEmbeddings()
docsearch = FAISS.from_texts(texts, embeddings)
query = "Explain who created the document and what is the purpose?"
docs = docsearch.similarity_search(query)
print(chain.run(input_documents=docs, question=query).strip())
query = "What is cap for insulin prescription?"
docs = docsearch.similarity_search(query)
print(chain.run(input_documents=docs, question=query).strip())
query = "Who represented Ukrain?"
docs = docsearch.similarity_search(query)
print(chain.run(input_documents=docs, question=query).strip())
While this was a fast and simple exercise, it shows how we can dramatically increase the accuracy of our PaLM 2 model by providing it with context from custom data sources (in this case from the PDF). Here LangChain made this integration simple by incorporating a similarity search (which retrieved the relevant parts of the document) as context for the prompt. LangChain makes it easy to include custom data sources and similarity search as parts of the pipelines that we build.
In the next article of this series, we will build a summarization app from the same PDF. Stay tuned.
Copyright © 2023 IDG Communications, Inc.







